Authors:
Anonymous
Abstract:Dialogue state tracking (DST) is an important step in dialogue management to keep track of users' beliefs. Existing works fine-tune all language model (LM) parameters to tackle the DST task, which requires significant data and computing resources for training and hosting. The cost grows exponentially in the real-world deployment where dozens of fine-tuned LM are used for different domains and tasks. To reduce parameter size and better utilize cross-task shared information, we propose to use soft prompt token embeddings to learn task properties. Without tuning LM parameters, our method drastically reduces the number of parameters needed to less than 0.5% of prior works while achieves better low-resource DST performance.
Authors:
Mohsen Fayyaz (University of Tehran)*; Ehsan Aghazadeh (University of Tehran); Seyed MohammadAli Modarressi (IUST); Mohammad Taher Pilehvar (Tehran Institute for Advanced Studies); Yadollah Yaghoobzadeh (University of Tehran ); Samira Ebrahimi Kahou (École de Technologie Supérieure)
Abstract:Current pre-trained language models rely on large datasets for achieving state-of-the-art performance. However, past research has shown that not all examples in a dataset are equally important during training. In fact, it is sometimes possible to prune a considerable fraction of the training set while maintaining the test performance. Established on standard vision benchmarks, two gradient-based scoring metrics for finding important examples are GraNd and its estimated version, EL2N. In this work, we employ these two metrics for the first time in NLP. We demonstrate that these metrics need to be computed after at least one epoch of fine-tuning and they are not reliable in early steps. Furthermore, we show that by pruning a small portion of the examples with the highest GraNd/EL2N scores, we can not only preserve the test accuracy, but also surpass it. This paper details adjustments and implementation choices which enable GraNd and EL2N to be applied to NLP.
Authors:
Yile Wang (Tsinghua University)*; Linyi Yang (Westlake University); Zhiyang Teng (Westlake University); Ming Zhou (SINOVATION VENTURES); Yue Zhang (Westlake University)
Abstract:Transformer-based models have gained much advance in recent years, becoming one of the most important backbones in natural language processing. Recent work shows that the attention mechanism in Transformer may not be necessary, both convolutional neural networks and multi-layer perceptron based models have been investigated as Transformer alternatives. In this paper, we consider a graph recurrent network for language model pre-training, which builds a graph structure for each sequence with local token-level communications, together with a sentence-level representation decoupled from other tokens. We find such architecture can give comparable results against Transformer-based ones in both English and Chinese language benchmarks. Moreover, instead of the quadratic complexity, our model has linear complexity and performs more efficiently during inference.
Authors:
Anonymous
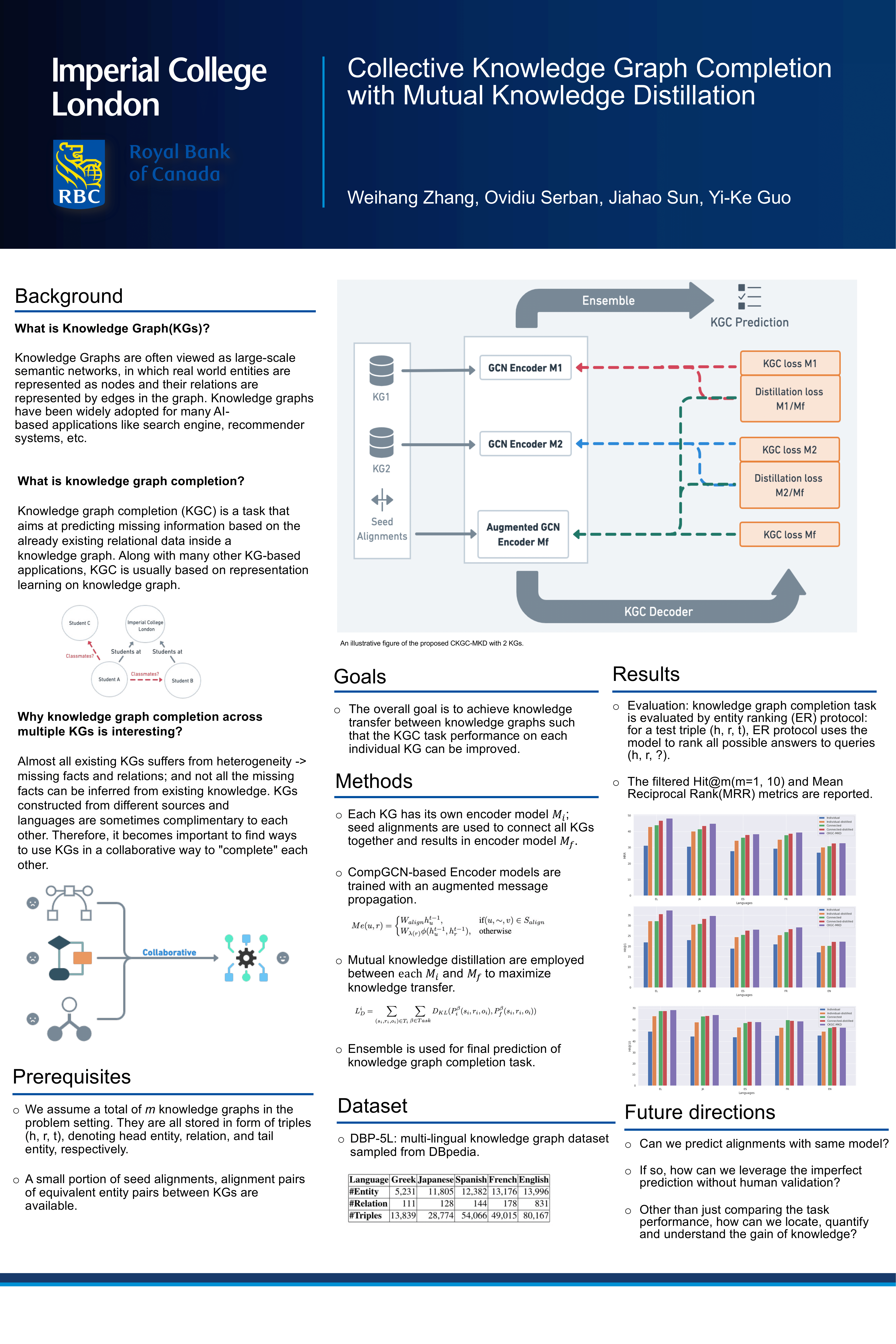
Abstract:Knowledge graph completion (KGC), the task that aims at predicting missing information based on the already existing relational data inside a knowledge graph(KG), has drawn significant attention in the recent years. However, predictive power of KGC methods is often limited by the completeness of the existing knowledge graphs. In monolingual and multilingual settings, KGs from different sources and languages are potentially complementary to each other. In this paper, we study the problem of multi-KG completion, where we focus on maximizing the collective knowledge from different KGs to alleviate the incompleteness on individual KGs. Specifically, we propose a novel method called CKGC-MKD that uses augmented CompGCN-based encoder models on both individual KGs and a large connected KG in which seed alignments between KGs are regarded as edges for message propagation. Additional mutual knowledge distillation are employed to maximize the knowledge transfer between the 'global' connected KG and the 'local' individual KGs. Experimental results on multilingual datasets has shown that our method outperforms all state-of-the-art models.
Authors:
Yuxiang Wu (University College London)*; Yu Zhao (Harbin Institute of Technology, Shenzhen); Baotian Hu (Harbin Institute of Technology, Shenzhen); Pasquale Minervini (University College London); Pontus Stenetorp (University College London); Sebastian Riedel (UCL)
Abstract:Access to external knowledge is essential for many natural language processing tasks, such as question answering and dialogue. Existing methods often rely on a parametric model that stores knowledge in its parameters, or use a retrieval-augmented model that has access to an external knowledge source. Parametric and retrieval-augmented models have complementary strengths in terms of computational efficiency and predictive accuracy. To combine the strength of both approaches, we propose the Efficient Memory-Augmented Transformer (EMAT) – it encodes external knowledge into a key-value memory and exploits the fast maximum inner product search for memory querying. Experiments on various knowledge-intensive tasks such as question answering and dialogue datasets show that, simply augmenting parametric models (T5-base) using our method produces more accurate results while retaining a high throughput. Compared to retrieval-augmented models, EMAT runs substantially faster across the board and produces more accurate results on WoW and ELI5.
Authors:
Shira Guskin (Intel)*; Moshe Wasserblat (INTEL); Chang Wang (intel); Haihao Shen (Intel)
Abstract:Limited computational budgets often prevent transformers from being used in production and from having their high accuracy utilized. A knowledge distillation approach addresses the computational efficiency by self-distilling BERT into a smaller transformer representation having fewer layers and smaller internal embedding. However, the performance of these models drops as we reduce the number of layers, notably in advanced NLP tasks such as span question answering. In addition, a separate model must be trained for each inference scenario with its distinct computational budget. Dynamic-TinyBERT tackles both limitations by partially implementing the Length Adaptive Transformer (LAT) technique onto TinyBERT, achieving x3 speedup over BERT-base with minimal accuracy loss. In this work, we expand the Dynamic-TinyBERT approach to generate a much more highly efficient model. We use MiniLM distillation jointly with the LAT method, and we further enhance the efficiency by applying low-bit quantization. Our quantized length-adaptive MiniLM model (QuaLA-MiniLM) is trained only once, dynamically fits any inference scenario, and achieves an accuracy-efficiency trade-off superior to any other efficient approaches per any computational budget on the SQuAD1.1 dataset (up to x8.8 speedup with <1% accuracy loss). The code to reproduce this work will be publicly released on Github soon.
Authors:
Lean Wang (Peking University)*; Lei Li (Peking University); Xu Sun (Peking University)
Abstract:Knowledge distillation (KD) is an effective framework to transfer knowledge from a large-scale teacher to a compact yet well-performing student. Previous KD practices for pre-trained language models transfer knowledge by aligning instance-wise outputs between the teacher and the student, while neglecting an important knowledge source, i.e., the gradient of the teacher. The gradient characterizes how the teacher responds to changes in inputs, which we assume is beneficial for the student to better approximate the underlying mapping function of the teacher. Therefore, we propose Gradient Knowledge Distillation (GKD) to incorporate the gradient alignment objective into the distillation process.Experimental results show that GKD outperforms previous KD methods in the student's performance. Further analysis shows that incorporating gradient knowledge makes the student behave more consistently with the teacher, improving the interpretability greatly.
Authors:
Pheobe Sun (University College Dublin; JP Morgan Chase & Co)*; Ruibo Shi (JP Morgan Chase & Co); Ahmad Emami (JP Morgan); Sean Moran (JP Morgan Chase & Co)
Abstract:While knowledge distillation has been proven effective in learning student models of smaller size on various tasks, a large amount of distillation training data is required to keep the performance of the student model competitive to the teacher model. Our research aims to further improve the efficiency in task-agnostic speech representation model pre-training. By perturbing the training data distribution, we distil a more robust task-agnostic speech representation model with a lower training data requirement. By learning representations from both a) the teacher model, which is trained via self-supervised learning (SSL) and b) the known effective hand-crafted features, we effectively regularize and compensate the representation loss due to the distillation process. Our proposed methods are evaluated on a number of downstream tasks and are shown to be effective in certain aspects, which prompts future research that builds on our work to develop efficient task-agnostic speech representation model distillation approaches.
Authors:
Oren Pereg (Intel Labs); Daniel Korat (Intel Labs); Moshe Wasserblat (INTEL); Lewis Tunstall (Hugging Face); Unso Eun Seo Jo (Hugging Face)*; Luke Bates (Ubiquitous Knowledge Processing Lab); Nils Reimers (cohere.ai)
Abstract:Recent few-shot learning methods, such as parameter-efficient fine-tuning (PEFT) and pattern exploiting training (PET), have achieved impressive results in label-scarce settings. However, they are difficult to employ since they are highly sensitive to handcrafted prompts, and typically require billion-parameter language models to achieve high accuracy. To address these shortcomings, we propose SetFit (Sentence Transformer Fine-tuning), an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers (ST). SetFit works by first fine-tuning a pretrained ST on a small number of labeled text pairs, in a contrastive Siamese manner. The resulting model is then used to generate rich text embeddings, which are used to train a classification head. This simple framework requires no prompts or verbalizers, and achieves high accuracy with orders of magnitude less parameters and runtime than existing techniques. Our experiments show that SetFit achieves results competitive with PEFT and PET techniques, and outperforms them on a variety of classification tasks.
Authors:
Vaibhav Singh (New York University); Vinayak Abrol (Indraprastha Institute of Technology Delhi)*; Karan Nathwani (Indian Institute of Technology, Jammu)
Abstract:Acoustic models typically employ production and perception based short-term features. In the context of deep models the acoustic information is hierarchically combined either 1) across frequency bands followed by temporal modelling similar to cepstrum features; or 2) across temporal trajectories followed by combination across spectral bands similar to relative spectra (RASTA) features. Such a processing pipeline is often implemented using low-rank methods to achieve low-footprint compared to SOTA models involving simultaneous spectral-temporal processing. However, very few attempts have been made to address the question of if and how such deep acoustic models flexibly integrate information from spectral or temporal features. In this work with the help of an Large vocabulary continuous speech recognition (LVCSR) case study, the geometry of loss landscape is used as a visualisation tool to understand the link between generalization error and spectral or temporal feature integration in learning task-specific information.
Authors:
Oren Pereg (Intel Labs)*; Daniel Korat (Intel Labs); Moshe Wasserblat (INTEL); Kfir Bar (College of Management)
Abstract:A fundamental task of fine-grained sentiment analysis is aspect term extraction.Supervised-learning approaches have demonstrated state-of-the art results for thistask; however, they underperform in few-shot scenarios, where labeled trainingdata is scarce. Prompt-based training has proven effective in few-shot sequenceclassification; however, it would not apply to token classification tasks. In thiswork we propose PATE (Prompt-based Aspect Term Extraction), a few-shotprompt-based method for the token classification task of aspect term extraction.We demonstrate that this method significantly outperforms the standard supervisedtraining approach in few-shot setups and make our code publicly available.
Authors:
Changho Shin (University of Wisconsin-Madison); Alice E Schoenauer-Sebag (Twitter)*
Abstract:A large number of natural language processing (NLP) datasets contain crowdsourced labels. Training set labels are usually generated using majority vote from individual rater's labels, which discards a significant amount of information. This paper focuses on improving data-efficiency when training a model for 'marginally abusive' Tweet classification. We compare majority vote to two families of alternative methods, changing the training process in two different steps: (1) aggregating individual labels using weak supervision to improve the quality of labels for model training, and (2) predicting individual labels using the multi-rater models proposed by Davani et al. [2022]. We find that majority vote is a strong baseline. Dawid-Skene and multi-rater models are not significantly better than the baseline, and the latter tend to be more susceptible to overfit. Finally, we also identify a number of practical considerations for the practitioner, such as setting a minimum number of labels per rater, or preferring soft to hard labels.
Authors:
Haihao Shen (Intel)*; Ofir Zafrir (Intel Labs, Israel); Bo Dong (Intel); Hengyu Meng (Intel); Xinyu Ye (Intel); Zhe Wang (Intel Corporation); Yi Ding (Intel); Hanwen Chang (Intel); Guy Boudoukh (Intel); Moshe Wasserblat (INTEL)
Abstract:Transformer-based language models have become the standard approach to solving natural language processing tasks. However, industry adoption usually requires the maximum throughput to comply with certain latency constraints that prevents Transformer models from being used in production. To address this gap, model compression techniques such as quantization and pruning may be used to improve inference efficiency. However, these compression techniques require specialized software to apply and deploy at scale. In this work, we propose a new pipeline for creating and running Fast Transformer models on CPUs, utilizing hardware-aware pruning, knowledge distillation, quantization, and our own Transformer inference runtime engine with optimized kernels for sparse and quantized operators. We demonstrate the efficiency of our pipeline by creating a Fast DistilBERT model showing minimal accuracy loss on the question-answering SQuADv1.1 benchmark, and throughput results under typical production constraints and environments. Our results outperform existing state-of-the-art Neural Magic's DeepSparse runtime performance by up to 50% and up to 4.1x performance speedup over ONNX Runtime.
Authors:
Joel Niklaus (University of Bern)*; Daniele Giofrè (Thomson Reuters Labs)
Abstract:Pretrained transformer models have achieved state-of-the-art results in many tasksand benchmarks recently. Many state-of-the-art (SOTA) Language Models (LM s),however, do not scale well above the threshold of 512 input tokens. In specializeddomains though (such as legal, scientific or biomedical), models often need toprocess very long text (sometimes well above 10000 tokens). Even though manyefficient transformers have been proposed (such as Longformer, BigBird or FNet),so far, only very few such efficient models are available for specialized domains.Additionally, since the pretraining process is extremely costly in general – buteven more so as the sequence length increases – it is often only in reach of largeresearch labs. One way of making pretraining cheaper is the Replaced TokenDetection ( RTD ) task, by providing more signal during training, since the losscan be computed over all tokens. In this work, we train Longformer models withthe efficient RTD task on legal data to showcase that pretraining efficient LMs ispossible using much less compute. We evaluate the trained models on challengingsummarization tasks requiring the model to summarize long texts to show to whatextent the models can achieve good performance on downstream tasks. We findthat both the small and base models outperform their baselines on the in-domainBillSum and out-of-domain PubMed tasks in their respective parameter range. Wepublish our code and models for research purposes.
Authors:
Shamil Ayupov (NRU HSE); Nadezhda Chirkova (Naver Labs Europe)*
Abstract:Pretrained Transformers achieve state-of-the-art performance in various code-processing tasks but may be too large to be deployed. As software development tools often incorporate modules for various purposes which may potentially use a single instance of the pretrained model, it appears relevant to utilize parameter-efficient fine-tuning for the pretrained models of code. In this work, we test two widely used approaches, adapters and LoRA, which were initially tested on NLP tasks, on four code-processing tasks. We find that though the efficient fine-tuning approaches may achieve comparable or higher performance than the standard, full, fine-tuning in code understanding tasks, they underperform full fine-tuning in code-generative tasks. These results underline the importance of testing efficient fine-tuning approaches on other domains than NLP and motivate future research in efficient fine-tuning for source code.
Authors:
Jiuzhou Han (Monash University)*; Ehsan Shareghi (Monash University)
Abstract:Large-scale pre-trained language models (PLMs) have advanced Graph-toText (G2T) generation by processing the linearised version of a graph. However, the linearisation is known to ignore the structural information. Additionally, PLMs are typically pre-trained on free text which introduces domain mismatch between pre-training and downstream G2T generation tasks. To address these shortcomings, we propose efficient graph masking pre-training strategies that neither require supervision signals nor adjust the architecture of the underlying pre-trained encoderdecoder model. When used with a pre-trained T5, our approach achieves new state-of-the-art results on WebNLG+2020 and EventNarrative G2T generation datasets. Our method also shows to be very effective in the low-resource setting. Our code is available at https://github.com/Jiuzhouh/Graph-Masking-Pre-training.
Authors:
Ryan Ong (Imperial College London)*; Jiahao Sun (Royal Bank of Canada); Ovidiu Serban (Data Science Institute, Imperial College London); Yike Guo (Imperial College London)
Abstract:Temporal knowledge graphs (TKGs) have been rising in popularity in many industrial applications. However, for TKG-based applications to perform accurately, we need to have a reliable temporal knowledge graph embedding (TKGE) model to capture the semantic meanings of entities and the relationship between entities. This is possible when we have many standardised academic TKGs that are well-connected with popular entities. However, in real-world settings, these well-connected TKGs are hardly available. Instead, real-world TKGs are usually more sparse and filled with noisy and less popular entities, which makes it very challenging to use to train an accurate TKGE model. In this paper, we ran five different TKGE models on the TKGQA mergers and acquisitions (M&A) dataset to assess the effectiveness of TKGE models in encoding real-world TKGs. Specifically, we selected M&As because it's common for a well-known company to merge/acquire a less popular/unknown company and as such we can evaluate the effectiveness of TKGE models in encoding the less well-known companies. The results show that TKGE models are ineffective in encoding less popular/unknown entities in sparse KGs; given the lack of information on the entities, the TKGE models find distinguishing them in the embedding space challenging.
Authors:
Hunter Lang (MIT)*; Monica N Agrawal (MIT); Yoon Kim (MIT); David Sontag (MIT)
Abstract:We demonstrate how to improve the zero-shot and few-shot performance of large language models (LLMs) by using the T-Few parameter-efficient fine-tuning method (Liu et al., 2022) with self-training or co-training. Our methods apply to settings where labeled data is very limited, but unlabeled data is plentiful. Specifically, we combine T-Few with (i) the co-training techniques of Lang et al. (2022a), and (ii) SETRED, a self-training algorithm that uses a very simple data selection criterion (Li and Zhou, 2005). By using the efficient T-Few method, we are able to scale co-training to larger models (from T0-3B to T0-11B) and cut down on wallclock training time, improving the zero-shot co-training results of Lang et al. 2022a). By performing multiple iterations of self- or co-training, we significantly improve over the few-shot performance of T-Few reported by Liu et al. (2022) without using any additional labeled data. Our methods are relatively fast (2.5 hours to self-train T0-11B on a single A100 80GB) and allow T0-11B to match the few-shot performance of models with an order of magnitude more parameters.
Authors:
Himanshu Gupta (Arizona State University)*; Shreyas Verma (Georgia Institute of Technology); Tarun Kumar (Birla Institute of Technology and Science, Pilani); Swaroop Ranjan Mishra (Arizona State University); Tamanna Agrawal (American Express); Amogh Badugu (Birla Institute of Technology & Science, Pilani ); Himanshu S Bhatt (Amex)
Abstract:NLP research has been focused on NER extraction and how to efficiently extract them from a sentence. However, generating relevant context of entities from a sentence has remained under-explored. In this work, we introduce the task Context-NER in which relevant context of an entity has to be generated. The extracted context may not be found exactly as a substring in the sentence. We also introduce the EDGAR10-Q dataset for the same, which is a corpus of 1,500 publicly traded companies. It is a manually created complex corpus and one of the largest in terms of number of sentences and entities (1 M and 2.8 M). We introduce a baseline approach that leverages phrase generation algorithms and uses the pre-trained BERT model to get 33% ROUGE-L score. We also do a one shot evaluation with GPT-3 and get 39% score, signifying the hardness and future scope of this task. We hope that addition of this dataset and our study will pave the way for further research in this domain.
Authors:
Zhaolin Li (Maastricht University)*; Jan Niehues (Karlsruhe Institute of Technology)
Abstract:When building state-of-the-art speech translation models, the need for large computational resources is a significant obstacle due to the large training data size and complex models. The availability of pre-trained models is a promising opportunity to build strong speech translation systems efficiently. In a first step, we investigate efficient strategies to build cascaded and end-to-end speech translation systems based on pre-trained models. Using this strategy, we can train and apply the models on a single GPU. While the end-to-end models show superior translation performance to cascaded ones, the application of this technology has a limitation on the need for additional end-to-end training data. In a second step, we proposed an additional similarity loss to encourage the model to generate similar hidden representations for speech and transcript. Using this technique, we can increase the data efficiency and improve the translation quality by 6 BLEU points in scenarios with limited end-to-end training data.
Authors:
Urchade Zaratiana (LIPN)*; Niama EL KHBIR (LIPN); Dennis Núñez-Fernández (Université Paris Cité); Pierre Holat (FiGroup); Nadi Tomeh (LIPN, Université Sorbonne Paris Nord); Thierry Charnois (University of Paris)
Abstract:Extractive question answering (ExQA) is an essential task for Natural Language Processing. The dominant approach to ExQA is one that represents the input sequence tokens (question and passage) with a pre-trained transformer, then uses two learned query vectors to compute distributions over the start and end answer span positions. These query vectors lack the context of the inputs, which can be a bottleneck for the model performance. To address this problem, we propose extit{DyREx}, a generalization of the extit{vanilla} approach where we dynamically compute query vectors given the input, using an attention mechanism through transformer layers. Empirical observations demonstrate that our approach consistently improves the performance over the standard one. The code and accompanying files for running the experiments are available at https://github.com/urchade/DyREx.
Authors:
Habib Hajimolahoseini (Huawei Toronto Research Centre)*; Walid Ahmed (Huawei); Mehdi Rezagholizadeh (Huawei Technologies); Vahid Partovi Nia (Huawei Noah's Ark Lab); Yang Liu (Huawei Canada)
Abstract:Low rank decomposition decomposes each fully-connected layer of the transformer modules into two smaller layers using Singular Value Decomposition. The state-of-the-art techniques usually apply LRD in a single-shot, where all of thelayers are decomposed simultaneously. In this paper, we propose and compare different strategies for applying low rank decomposition to compress pre-trained transformer based models. These strategies include: layer-by-layer and progressive decomposition. We observe that progressive low rank decomposition, in which the rank is decreased incrementally results in a higher accuracy after decomposition comparing to single-shot and layer-by-layer low rank decomposition. Furthermore, in contrast with many of state-of-the-art compression methods where intensive pre-training of the compressed model is necessary, we show that progressive LRD can provide promising performance by compressing the model in the fine-tuning stage.
Authors:
Jingyu Zhang (Johns Hopkins University)*; James Glass (Massachusetts Institute of Technology); Tianxing He (University of Washington)
Abstract:Existing work on controlled text generation (CTG) assumes a control interface of categorical attributes. In this work, we propose a natural language interface, where we craft a PCFG to embed the control attributes into natural language commands and propose variants of existing CTG models that take commands as input. We design tailored experiments to test model's generalization abilities. The results show our PCFG-based command generation approach is effective for handling unseen commands compared to fix-set templates, and our proposed NL models can effectively generalize to unseen attributes.
Authors:
Mojtaba Valipour (University of Waterloo)*; Mehdi Rezagholizadeh (Huawei Technologies); Ivan Kobyzev (Huawei); Ali Ghodsi (University of Waterloo)
Abstract:With the ever-growing size of pre-trained models (PMs), fine-tuning has become more expensive and resource hungry. As a remedy, low-rank adapters (LoRA) keep the main pre-trained weights of the model frozen and just introduce some learnable truncated SVD modules (so called LoRA blocks) to the model. While LoRA blocks are parameter efficient, they suffer from two major problems: first, the size of these blocks is fixed and cannot be modified after training (for example if we need to change the rank of LoRA blocks, then we need to train them from scratch); second, optimizing their rank requires an exhaustive search. In this work, we introduce a dynamic low rank adaptation (DyLoRA) solution to address these two problems together. Our DyLoRA method trains LoRA blocks for a range of ranks instead of a single rank by sorting out the representation learned at different ranks during training. We evaluate our solution on different tasks in the GLUE benchmark using the RoBERTa model. Our results show that we can train DyLoRA at least $7x$ faster than LoRA without compromising the performance significantly. Moreover, our models can perform consistently well on a much larger range of ranks compared to LoRA.
Authors:
Ershad Banijamali (Amazon Inc.)*; Pegah Kharazmi (Amazon); Sepehr Eghbali (Amazon); Jixuan Wang (Amazon); Clement Chung (Amazon); Samridhi Choudhary (Amazon Inc.)
Abstract:Large transformer-based models have demonstrated state of the art results on several Natural Language Understanding (NLU) tasks. However, their deployment comes at the cost of increased footprint and inference latency, limiting their adoption to real-time applications, especially on resource constrained devices. In order to optimize the trade-off between model accuracy, footprint and inference latency, we propose Pyramid Dynamic Inference (PDI), a scheme that encourages fast inference by introducing early inference routes in a transformer model, with a focus on boosting the performance of early exit heads. Owing to the limited capacity of the earlier transformer layers to extract complex semantics, the exit heads for these layers typically display high confidence only over easy data samples. PDI aims to recover this by applying a pyramidal structure to the classification heads that allows for more confident early inference by injecting stronger classifiers at earlier layers. It also prevents a significant increase in the model footprint by gradually shrinking the classifiers as the semantic capacity of the deeper transformer layers increase. We validate the efficiency of the PDI scheme on the GLUE benchmark, where we show that PDI consistently outperforms FastBert on both accuracy and latency. Compared to the original 6-layer DistilBert, PDI achieves on average up to 3.66x speedup with 29% fewer parameters with only 3.3% accuracy degradation.
Authors:
Mark Schoene (Technische Universität Dresden)*; Khaleelulla Khan Nazeer (Technische Universität Dresden); David Kappel (Postdoc, Ruhr Uni Bochum); Christian Mayr (TU Dresden); Anand Subramoney (Ruhr University Bochum)
Abstract:Transformers have displaced recurrent neural networks (RNN) for language modelling due to their scalability on ubiquitous GPUs. However, resource constrained systems are confronted with the high computational cost and memory footprint of both training and inference with transformer language models.RNN language models are a potential alternative, but there are gaps to bridge in terms of capabilities. The sequential dependence of activations together with the memory and computational requirements arising from propagating the activations of all the neurons at every time step to every connected neuron make RNNs harder to train efficiently. We propose an architecture inspired by biological neuron dynamics, that makes the communication between RNN units sparse and discrete along the forward direction.We demonstrate our sparsity model with a gated recurrent unit (GRU). The recurrent units emit discrete events for communication triggered by a gating mechanism. Thus, no information needs to be communicated to other units in the absence of events. We show that this makes backpropagation through time (BPTT) and inference computationally sparse. With access to neuromorphic accelerators this unstructured sparsity can realize efficiency gains for energy and memory usage. Overall, we achieve efficiency without compromising task performance, demonstrating competitive performance compared to state-of-the-art recurrent network models in language modelling.
Authors:
Heitor R Guimarães (Institut National de la Recherche Scientifique)*; Arthur S Pimentel (Institut National de la Recherche Scientifique (INRS)); Anderson ARA R. Avila (Huawei Noah's Ark Lab); Mehdi Rezagholizadeh (Huawei Technologies); Tiago H Falk (INRS-EMT)
Abstract:Self-supervised speech representation learning aims to extract meaningful factors from the speech signal that can later be used across different downstream tasks, such as speech and/or emotion recognition. Existing models, such as HuBERT, however, can be fairly large thus may not be suitable for edge speech applications. Moreover, realistic applications typically involve speech corrupted by noise and room reverberation, hence models need to provide representations that are robust to such environmental factors. In this study, we build on the so-called DistilHuBERT model, which distils HuBERT to a fraction of its original size, with three modifications, namely: (i) augment the training data with noise and reverberation, while the student model needs to distill the clean representations from the teacher model; (ii) introduce a curriculum learning approach where increasing levels of noise are introduced as the model trains, thus helping with convergence and with the creation of more robust representations; and (iii) introduce a multi-task learning approach where the model also reconstructs the clean waveform jointly with the distillation task, thus also acting as an enhancement step to ensure additional environment robustness to the representation. Experiments on three SUPERB tasks show the advantages of the proposed method not only relative to the original DistilHuBERT, but also to the original HuBERT, thus showing the advantages of the proposed method for ``in the wild'' edge speech applications.
Authors:
Anonymous
Abstract:Prompt-tuning has become an increasingly popular parameter-efficient method for steering large pretrained language models to downstream tasks. However, both discrete prompting and continuous prompting assume fixed prompts for all data samples within a task, neglecting the fact that inputs vary greatly in some tasks such as open-domain dialogue generation. In this paper, we present a novel, instance-specific prompt-tuning algorithm for dialogue generation. Specifically, we generate prompts based on instance-level control code, rather than the conversation history, to explore their impact on controlled dialogue generation. Experiments on popular open-domain dialogue datasets, evaluated with both automated metrics and human evaluation, demonstrate that our method is superior to prompting baselines and comparable to fine-tuning with only 5%-6% of total parameters.
Authors:
Alon Albalak (University of California, Santa Barbara)*; Akshat Shrivastava (Meta); Chinnadhurai Sankar (Facebook AI); Adithya Sagar (Facebook AI); Mike Ross (Meta)
Abstract:Multi-task learning (MTL), instruction tuning, and prompting have recently been shown to improve the generalizability of large language models to new tasks. However, the benefits of such methods are less well-documented in smaller language models, with some studies finding contradictory results. In this work, we explore and isolate the effects of (i) model size, (ii) general purpose MTL, (iii) in-domain MTL, and (iv) instruction tuning for models with fewer than 500 million parameters. Our experiments demonstrate that general purpose MTL improves performance by 31% on average, with further in-domain MTL improving performance by an additional 37.6% on average. We find that instruction tuning provides a modest 2% performance improvement for small models.
Authors:
Abderrahim Fathan (Computer Research Institute of Montreal (CRIM), Montreal, Quebec, Canada)*; Jahangir Alam (Computer Research Institute of Montreal (CRIM), Montreal (Quebec) Canada); Woo Hyun Kang (Computer Research Institute of Montreal)
Abstract:One of the most widely used self-supervised speaker verification system training methods is to optimize the speaker embedding network in a discriminative fashion using clustering algorithm-driven pseudo-labels. Although the pseudo-label-based self-supervised training scheme showed impressive performance, recent studies have shown that label noise can significantly impact the performance. In this paper, we have explored various pseudo-labels driven by different clustering algorithms and conducted a fine-grained analysis of the relationship between the quality of the pseudo-labels and the speaker verification performance. From our experimental results, we shed light on several previously unexplored and overlooked aspects of the pseudo-labels that can have an impact on the speaker verification performance.Moreover, we could observe that the self-supervised speaker verification performance is heavily dependent on multiple qualitative aspects of the clustering algorithm that was used for generating the pseudo-labels. Furthermore, we show that the speaker verification performance can be severely degraded from overfitting to the noisy pseudo-labels and that the mixup strategy can mitigate the memorization effects of label noise.
Authors:
Andrew Rock (Untether AI)*; Omar M Khalil (Untether AI); Ofer Shai (Untether AI); Paul Grouchy (University of Toronto)
Abstract:Given the general trend towards large models in the deep learning community (particularly in the space of Transformers), much work has been done with the goal of reducing the cost associated with inference. In this work, we reach a new low, quantizing all weights and activations of BERT to 8-bit integers. GELU and exp are implemented with integer lookup tables, achieving optimal INT8 quantization error. We introduce a generalized technique to compute operations frequently missing on integer-only hardware (e.g. divisions, roots) via an efficient instantiation of binary search. By applying it to intermediate computations in Softmax and LayerNorm, we obtain accurate implementations of these layers as well. We evaluate our approach on several GLUE tasks, demonstrating minimal accuracy degradation.
Authors:
Soumajyoti Sarkar (Amazon Web Services)*; Saab Mansour (AWS); Sailik Sengupta (Amazon); Sheng Zha (Amazon Web Services); Kaixiang Lin (amazon)
Abstract:The use of multilingual language models for tasks in low and high-resource languages has been a success story in deep learning. In recent times, Arabic has been receiving widespread attention on account of its dialectal variance. While prior research studies have tried to adapt these multilingual models for dialectal variants of Arabic, it still remains a challenging problem owing to the lack of sufficient monolingual dialectal data and parallel translation data of such dialectal variants. It remains an open problem on whether the limited dialectical data can be used to improve the models trained in Arabic on its dialectal variants. First, we show that multilingual-BERT (mBERT) incrementally pretrained on Arabic monolingual data takes less training time and yields comparable accuracy when compared to our custom monolingual Arabic model and beat existing benchmarks (by an avg metric of +6.41). We then explore two continual pre-training methods-- (1) using small amounts of dialectical data for continual finetuning and (2) parallel Arabic to English data and a Translation Language Modeling loss function. We show that both approaches help improve performance on dialectal classification tasks (+4.64 avg. gain) when used on monolingual models.
Authors:
Muhammad N ElNokrashy (Microsoft)*; Badr AlKhamissi (Meta AI); Mona Diab (GWU)
Abstract:Language Models pretrained on large textual data have been shown to encode different types of knowledge simultaneously. Usually, only the features from the last layer are used when adapting to new tasks or data. We put forward that in using or finetuning deep pretrained models, intermediate layer features that may be relevant to the downstream task are buried too deep to be used efficiently in terms of needed samples or steps. To test this, we propose a new layer fusion method: Depth-Wise Attention (DWAtt), to help re-surface signals from non-final model layers. We compare DWAtt to a basic concatenation-based layer fusion method (Concat), and compare both to a deeper model baseline---all kept within a similar parameter budget. Our findings show that DWAtt and Concat are more step- and sample-efficient than the baseline, especially in the few-shot setting. DWAtt outperforms Concat on larger data sizes. On CoNLL-03 NER, layer fusion shows 3.68-9.73% F1 gain at different few-shot sizes. The layer fusion models presented significantly outperform the baseline in various training scenarios with different data sizes, architectures, and training constraints.
Authors:
Mojtaba Valipour (University of Waterloo)*; Bowen You (University of Waterloo); Maysum Panju (University of Waterloo); Ali Ghodsi (University of Waterloo)
Abstract:Symbolic regression is the task of identifying a mathematical expression that best fits a provided dataset of input and output values. Due to the richness of the space of mathematical expressions, symbolic regression is generally a challenging problem. While conventional approaches based on genetic evolution algorithms have been used for decades, deep learning-based methods are relatively new and an active research area. In this work, we present SymbolicGPT, a novel transformer-based language model for symbolic regression. This model exploits the advantages of probabilistic language models like GPT, including strength in performance, scalability, and flexibility. Through comprehensive experiments, we show that our model performs strongly compared to competing models.
Authors:
Anonymous
Abstract:Language Models (LMs) are pretrained on large unlabeled corpora through selfsupervision tasks and have become ubiquitous to several NLP applications. Recent trends indicate that the generalization capability of Large LMs (LLMs) improves tremendously with increasing model capacity and size of the pretraining dataset. However, this also results in inefficiencies owing to higher training times, compute requirements and environmental impact. Previous works have mostly addressed the inefficiency concerns with respect to improving sample efficiency, architecture and training loss objective with little focus on data optimization. In this work, we explore if it is possible to use only highly informative subsets of the training data to train LLMs while maintaining their performance. We build upon the work done in informative data subset selection and propose INGENIOUS, a framework that selects highly representative subsets of the training corpus by optimizing a submodular function. We show INGENIOUS can be adopted for the scale of LLM training and empirically demonstrate that the proposed framework achieves ∼ 99% of original BERT performance in about ∼ 35% of the original training time.
Authors:
Tanish Lad (IIIT Hyderabad)*; Himanshu Maheshwari (Adobe India); Shreyas Kottukkal (IIIT Hyderabad); Radhika Mamidi (IIIT Hyderabad)
Abstract:Pre-training a language model and then fine-tuning it for downstream tasks has demonstrated state-of-the-art results for various NLP tasks. Pre-training is usually independent of the downstream task, and previous works have shown that this pre-training alone might not be sufficient to capture the task-specific nuances. We propose a way to tailor a pre-trained BERT model for the downstream task via task-specific masking before the standard supervised fine-tuning. For this, a word list is first collected specific to the task. For example, if the task is sentiment classification, we collect a small sample of words representing both positive and negative sentiments. Next, a word's importance for the task, called the word's task score, is measured using the word list. Each word is then assigned a probability of masking based on its task score. We experiment with different masking functions that assign the probability of masking based on the word's task score. The BERT model is further trained on MLM objective, where masking is done using the above strategy. Following this standard supervised fine-tuning is done for different downstream tasks. Results on these tasks show that the selective masking strategy outperforms random masking, indicating its effectiveness.
Authors:
Aref Jafari (University of Waterloo)*; Mehdi Rezagholizadeh (Huawei Technologies); Ali Ghodsi (University of Waterloo)
Abstract:Knowledge distillation (KD) is one of the prominent techniques for model compression. Although conventional KD is effective for matching the two networks over the given data points, there is no guarantee that these models would match in other areas for which we do not have enough training samples. In this work, we address this problem by generating new auxiliary training samples based on extracting knowledge from the backward pass and identifying the areas where the student diverges greatly from the teacher. This is done by perturbing data samples in the direction of the gradient of the difference between the student and the teacher. We studied the effect of the proposed method on various tasks in different domains, including images and NLP tasks with considerably smaller student networks. Our experiments, show the proposed method got superior results over other baselines.
Authors:
Canyu Chen (Illinois Institute of Technology)*; Kai Shu (Illinois Institute of Technology)
Abstract:Recent advances in large pre-trained language models (PLMs) lead to impressive gains on natural language understanding (NLU) tasks with task-specific fine-tuning. However, directly fine-tuning PLMs heavily relies on sufficient labeled training instances, which are usually hard to obtain. Prompt-based tuning on PLMs has shown to be powerful for various downstream few-shot tasks. Existing works studying prompt-based tuning for few-shot NLU tasks mainly focus on deriving proper label words with a verbalizer or generating prompt templates to elicit semantics from PLMs. In addition, conventional data augmentation strategies such as synonym substitution are also widely adopted in low-resource scenarios. However, the improvements they bring to prompt-based few-shot learning have been demonstrated to be marginal. Thus, an important research question arises as follows: how to design effective data augmentation methods for prompt-based few-shot tuning? To this end, considering the label semantics are essential in prompt-based tuning, we propose a novel label-guided data augmentation framework PromptDA, which exploits the enriched label semantic information for data augmentation. Extensive experiment results on few-shot text classification tasks show that our proposed framework achieves superior performances by effectively leveraging label semantics and data augmentation for natural language understanding.
Authors:
Reshmi Ghosh (Microsoft Corp.)*; Harjeet S Kajal (University of Massachusetts Amherst); Sharanya Kamath (University of Massachusetts Amherst); Dhuri Shrivastava ( University of Massachusetts, Amherst); Samyadeep Basu (UMD); Soundararajan Srinivasan (Microsoft)
Abstract:Breaking down a document or a conversation into multiple contiguous segments based on its semantic structure is an important and challenging problem in NLP, which can assist many downstream tasks. However, current works on topic segmentation often focus on segmentation of structured texts. In this paper, we comprehensively analyze the generalization capabilities of state-of-the-art topic segmentation models on unstructured texts. We find that: (a) Current strategies of pre-training on a large corpus of structured text such as Wiki-727K do not help in transferability to unstructured texts. (b) Training from scratch with only a relatively small-sized dataset of the target unstructured domain improves the segmentation results by a significant margin
Authors:
Shafi Goldwasser (UC Berkeley); David Gruber (Project CETI); Adam Tauman Kalai (Microsoft Research); Orr Paradise (UC Berkeley)*
Abstract:Unsupervised translation generally refers to the challenging task of translating between two languages without parallel translations, i.e., from two separate monolingual corpora.In this work, we propose an information-theoretic framework of unsupervised translation that can be well suited even for the case where the source language is that of highly intelligent animals, such as whales, and the target language is a human language, such as English.We identify two conditions that combined allow for unsupervised translation: (1) there is access to an prior distribution over the target language that estimates the likelihood that a sentence was translated from the source language, and (2) most alterations of translations are deemed implausible by the prior. We then give an (inefficient) algorithm which, given access to the prior and unlabeled source examples as input, outputs a provably accurate translation function. We prove upper bounds on the number of samples needed by our algorithm. Surprisingly, our analysis suggests that the amount of source data required for unsupervised translation is not significantly greater than that of supervised translation.To support the viability of our theory, we propose a simplified probabilistic language model: the random sub-tree language model, in which sentences correspond to paths in a randomly-labeled tree. We prove that random sub-tree languages satisfy conditions (1-2) with high probability, and are therefore translatable by our algorithm.Our theory is motivated by a recent initiative to translate whale communication using modern machine translation techniques. The recordings of whale communications that are being collected have no parallel human-language data. Our work seeks to inform this ambitious effort by modeling unsupervised translation. We are further motivated by recent empirical work, reported in the machine learning literature, demonstrating that unsupervised translation is possible in certain settings.
Accepted papers

|

|

|
{kind=link}
{kind=link}
{kind=link}